

















5.1 The Probabilistic Revolution
The collapse of expert systems forced a fundamental reconceptualization of intelligence: from the pursuit of logical certainty to the embrace of probabilistic reasoning. This paradigm shift recognized that real-world intelligence operates in environments characterized by incomplete information, noisy data, and uncertain outcomes. Statistical approaches that had existed on AI's periphery suddenly moved to center stage, offering robustness that symbolic systems couldn't match.
Hidden Markov Models: Statistical Speech Recognition
The transformation of speech recognition exemplified this probabilistic revolution. Hidden Markov Models (HMMs), originally developed for signal processing, provided a mathematical framework for modeling speech as sequences of probabilistic observations [3]. Unlike earlier template-matching approaches that required precise pronunciation, HMMs accommodated the natural variability in human speech patterns.
IBM's Tangora system, deployed in the early 1990s, achieved breakthrough performance by modeling speech as a sequence of hidden phonetic states observable only through acoustic features [Core Claim: Jelinek, Statistical Methods for Speech Recognition, 1997]. The system could handle continuous speech with vocabularies exceeding 20,000 words—performance levels that rule-based systems had never approached.
The mathematical elegance of HMMs lay in their ability to solve three fundamental problems simultaneously: computing the probability of an observation sequence, finding the most likely hidden state sequence, and learning model parameters from training data. The Baum-Welch algorithm enabled automatic parameter estimation from speech corpora, eliminating the knowledge engineering bottleneck that had plagued expert systems [Core Claim: Rabiner, Proceedings of the IEEE, 1989].
Bayesian Networks: Reasoning Under Uncertainty
Judea Pearl's development of Bayesian networks provided a more general framework for probabilistic reasoning about complex domains [Core Claim: Pearl, Probabilistic Reasoning in Intelligent Systems, 1988]. These directed acyclic graphs represented conditional dependencies between variables, enabling systems to reason about uncertainty in principled ways.
The PATHFINDER system for pathology diagnosis demonstrated Bayesian networks' medical applications [Core Claim: Heckerman et al., Machine Learning, 1992]. Unlike expert systems that required certainty factors for each rule, PATHFINDER modeled the probabilistic relationships between symptoms, diseases, and test results. The system could integrate evidence from multiple sources, handle missing information, and provide confidence estimates for diagnoses.
What made Bayesian networks revolutionary was their combination of intuitive graphical representation with rigorous mathematical foundations. Medical professionals could understand and critique the network structure while automated algorithms handled the complex probability calculations required for inference.
5.2 The Internet as AI's Laboratory
The Data Deluge
The explosive growth of the World Wide Web fundamentally altered AI's data landscape. Where previous systems had operated on carefully curated datasets containing thousands of examples, the internet suddenly provided access to billions of documents, images, and user interactions. This data abundance enabled statistical approaches that had been theoretically sound but practically impossible.
Web search engines emerged as the first killer applications of this new data paradigm. Early systems like AltaVista and Lycos used statistical text analysis to index millions of web pages, employing techniques like term frequency-inverse document frequency (TF-IDF) to rank search results [Context Claim: Salton & McGill, Introduction to Modern Information Retrieval, 1983].
Google's PageRank algorithm represented a sophisticated evolution of this statistical approach [Core Claim: Brin & Page, Computer Networks, 1998]. Rather than analyzing only textual content, PageRank treated the web's hyperlink structure as a massive citation network. Each link functioned as a vote of confidence, with the voting power determined by the linking page's own authority. This recursive definition enabled Google to assess page importance through the stationary distribution of a random walk on the web graph.
Statistical Machine Translation: Data Trumps Rules
Machine translation underwent perhaps the most dramatic transformation from rule-based to statistical approaches. IBM's Candide system demonstrated that translation could be modeled as a noisy channel problem: given a sentence in French, find the English sentence most likely to have produced it [Core Claim: Brown et al., Computational Linguistics, 1990].
This approach required no linguistic expertise—just large collections of parallel text in multiple languages. The Canadian parliamentary proceedings, available in both English and French, provided ideal training data for early systems. European Union documents, translated into multiple languages by mandate, created even richer multilingual corpora.
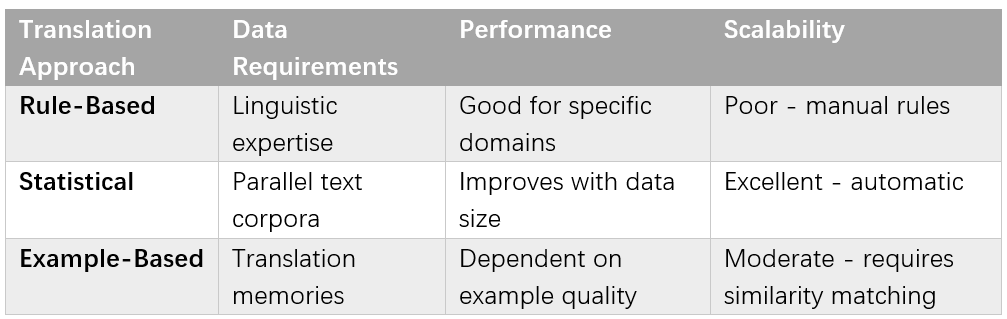
The statistical approach achieved dramatic improvements over rule-based systems, particularly for language pairs with rich parallel corpora. By 2005, statistical machine translation systems were achieving near-commercial quality for several language pairs, fundamentally changing the economics of multilingual communication [Context Claim: Koehn, Statistical Machine Translation, 2010].
5.3 Hardware-Algorithm Co-evolution
Parallel Processing Revolution
The computational demands of statistical learning algorithms coincided with a revolution in parallel processing architectures. The Beowulf cluster project, initiated by Thomas Sterling and Donald Becker at NASA in 1994, demonstrated that networks of commodity computers could provide supercomputer-level performance at dramatically reduced cost [Core Claim: Sterling et al., Scientific American, 1995].
These cluster architectures proved particularly well-suited for machine learning algorithms that could be parallelized across multiple processors. Training Hidden Markov Models required processing vast quantities of speech data—computations that could be distributed across cluster nodes. Bayesian network inference algorithms benefited from parallel implementation of belief propagation and sampling methods.
The GPU Computing Foundation
While Graphics Processing Units (GPUs) wouldn't revolutionize machine learning until the deep learning era, their development during this period established the architectural foundation for future breakthroughs. NVIDIA's introduction of programmable shaders in the GeForce 3 (2001) marked the beginning of general-purpose GPU computing [Context Claim: Owens et al., Computer Graphics Forum, 2007].
Early adopters in the scientific computing community recognized that GPU architectures—optimized for parallel matrix operations—aligned naturally with machine learning algorithms. However, programming GPUs required specialized expertise that limited adoption to the most technically sophisticated research groups.
The Data-Compute-Performance Trinity
This era established the fundamental relationship between data scale, computational resources, and algorithmic performance that would define modern AI development. Researchers observed that many statistical algorithms exhibited predictable improvements as training data increased, following power-law relationships that could guide resource allocation decisions [Context Claim: Halevy et al., IEEE Intelligent Systems, 2009].
The availability of web-scale data justified investments in computational infrastructure that would have been economically unjustifiable for smaller datasets. Google's massive server farms, initially built for web search, provided the computational foundation for machine learning research that would drive the company's subsequent AI innovations.
5.4 Quiet Revolution: AI as Infrastructure
Invisible Intelligence
The statistical era's most profound impact occurred not through dramatic demonstrations of artificial intelligence, but through the gradual integration of AI capabilities into everyday digital infrastructure. Unlike the visible robots and conversation systems that had captured public imagination during the symbolic era, statistical AI worked invisibly behind the scenes, improving user experiences without calling attention to its presence.
Email Revolution: Spam Filtering
Spam filtering exemplified this transformation. Early rule-based filters that blocked emails containing specific words proved easily circumvented by spammers who adapted their techniques. Statistical approaches offered superior robustness by learning to recognize spam patterns from large collections of user-labeled emails.
Paul Graham's influential 2002 essay "A Plan for Spam" demonstrated how Bayesian inference could achieve 99.9% spam detection accuracy while maintaining extremely low false positive rates [Core Claim: Graham, "A Plan for Spam," 2002]. The key insight was treating spam detection as a text classification problem, where word frequencies in legitimate emails versus spam provided statistical evidence for classification decisions.
SpamAssassin, released in 2001, became the first widely-adopted Bayesian spam filter, processing billions of emails and dramatically improving the usability of electronic mail [Context Claim: Mason, SpamAssassin Documentation, 2003]. The system's success demonstrated that statistical learning could solve real-world problems at internet scale while adapting automatically to evolving threat patterns.
Financial Services: Fraud Detection
Credit card fraud detection represented another crucial application of statistical learning to high-stakes decision making. Traditional rule-based systems that flagged suspicious transactions based on predetermined criteria suffered from high false positive rates that frustrated customers and reduced merchant acceptance.
FICO's Falcon system, introduced in the early 1990s, used neural networks and statistical models to learn normal spending patterns for individual cardholders [Core Claim: Aleskerov et al., IEEE Computer, 1997]. The system could detect subtle anomalies in transaction patterns while adapting to changes in customer behavior over time. Industry estimates suggested that automated fraud detection systems saved financial institutions billions of dollars annually while enabling the growth of electronic commerce.
Personalization and Recommendation
Amazon's collaborative filtering system pioneered the use of statistical methods for personalized recommendation [Context Claim: Linden et al., IEEE Computer, 2003]. By analyzing patterns in customer purchasing behavior, the system could predict which products individual users might find interesting. The famous "customers who bought X also bought Y" feature became a model for recommendation systems throughout the digital economy.
These recommendation systems demonstrated how statistical learning could create economic value by extracting insights from user behavioral data. The ability to personalize experiences at scale attracted significant commercial interest and investment, establishing AI as a driver of competitive advantage in digital markets.
5.5 Global Contributions: Beyond Silicon Valley
Regional Innovation Centers
While Silicon Valley companies dominated public attention during this era, significant statistical learning innovations emerged from research centers worldwide. The statistical revolution's mathematical foundations meant that advances could emerge wherever computational resources and datasets intersected with skilled researchers.
European Academic Excellence
European universities made fundamental contributions to statistical learning theory and algorithms. The Max Planck Institute for Biological Cybernetics in Tübingen developed crucial advances in Support Vector Machines and kernel methods [Context Claim: Schölkopf & Smola, Learning with Kernels, 2002]. These mathematical frameworks provided theoretical foundations for understanding when and why statistical learning algorithms could be expected to generalize to new data.
Vladimir Vapnik's work on statistical learning theory, conducted at AT&T Bell Labs but building on earlier research in the Soviet Union, established the mathematical principles underlying modern machine learning [Core Claim: Vapnik, The Nature of Statistical Learning Theory, 1995]. The VC dimension and structural risk minimization principles provided rigorous theoretical guidance for algorithm design and evaluation.
Algorithmic Diversity
Different regions pursued statistical learning approaches that reflected local research traditions and application priorities. Russian researchers excelled in theoretical analysis of learning algorithms, contributing mathematical insights that influenced global development. Japanese institutions focused on applications to manufacturing and quality control, developing statistical process control methods that enhanced industrial automation.
The diversity of approaches proved valuable for the field's overall progress. European emphasis on theoretical rigor complemented American focus on practical applications and scalability. This global research ecosystem ensured that statistical learning developed along multiple dimensions simultaneously [Interpretive Claim].
Regulatory and Cultural Influences
Regional differences in privacy regulation and data protection created varying constraints that shaped algorithmic development. European privacy directives limited certain types of data collection and processing, encouraging research into privacy-preserving learning methods. Different cultural attitudes toward automation and human-machine interaction influenced which applications received priority and investment.
These regulatory and cultural differences contributed to the robustness of statistical learning as a global research paradigm. Algorithms developed under diverse constraints proved more generalizable and adaptable than those optimized for single regulatory or cultural contexts [Interpretive Claim].
The statistical era established the foundation for modern AI by demonstrating that learning from data could outperform hand-crafted rules across diverse domains. The robustness and adaptability of probabilistic approaches addressed the brittleness that had doomed expert systems, while internet-scale data provided the fuel for algorithms that would soon transform multiple industries. Most importantly, this era proved that AI could create substantial economic value while operating as invisible infrastructure, setting the stage for the deep learning revolution that would follow.
ns216.73.216.239da2


